In today's digital landscape, where downtime can translate to significant losses in revenue and reputation, ensuring high availability (HA) of your systems is paramount. High availability architecture is a framework designed to minimize downtime and maintain continuous access to services, even in the face of hardware failures, software glitches, or natural disasters. However, achieving high availability requires careful planning and adherence to specific requirements. In this blog post, we'll delve into the fundamental requirements of high availability architecture to help you understand what it takes to build resilient systems. First, though, let’s discuss the basics of high availability architecture.
What is high availability?
High availability (HA) refers to the ability of a system or service to remain operational and accessible for a high percentage of time, typically measured in terms of uptime percentage. It involves setting up backup systems, automatically switching to them in the case of an issue, and distributing resources across multiple locations to avoid downtime.
What is high availability architecture?
High availability architecture is a framework designed to minimize downtime and maintain continuous access to services, even in the face of hardware failures, software glitches, or natural disasters. It prioritizes system reliability and seamless user experience through robust redundancy and failover mechanisms.
How does high availability architecture work?
High availability architecture employs redundant components and fault-tolerant mechanisms to minimize downtime and ensure continuous operation. This architecture distributes workload across multiple servers or data centers, allowing the system to withstand hardware failures, software errors, or network issues without disrupting service. Automated failover processes detect failures and seamlessly redirect traffic to healthy components, ensuring uninterrupted access to services.
Why is high availability architecture important?
Revenue Protection:
Helps safeguard against major financial losses by reducing system downtime, which is critical for online businesses, e-commerce platforms, and financial services that rely on uninterrupted service to maintain revenue streams.
Enhanced Customer Satisfaction:
With round-the-clock access to services and applications, businesses can build stronger customer trust and loyalty. A consistent, always-on service creates an exceptional experience that boosts overall customer satisfaction.
Business Continuity:
Keeps your operations running smoothly, even when systems experience failures or disruptions. This is vital for organizations that depend on technology to maintain service levels without significant interruptions.
Stronger Brand Reputation:
By minimizing the risk of system outages, companies can protect their reputation and prevent customer dissatisfaction. Ensuring a stable, reliable service helps maintain trust and avoid potential damage to the brand.
Improved Productivity:
Ensures employees have access to the tools they need without disruption, helping them stay focused and productive. This seamless connectivity fosters an efficient work environment, even during periods of unforeseen system hiccups.
What is an example of high availability architecture?
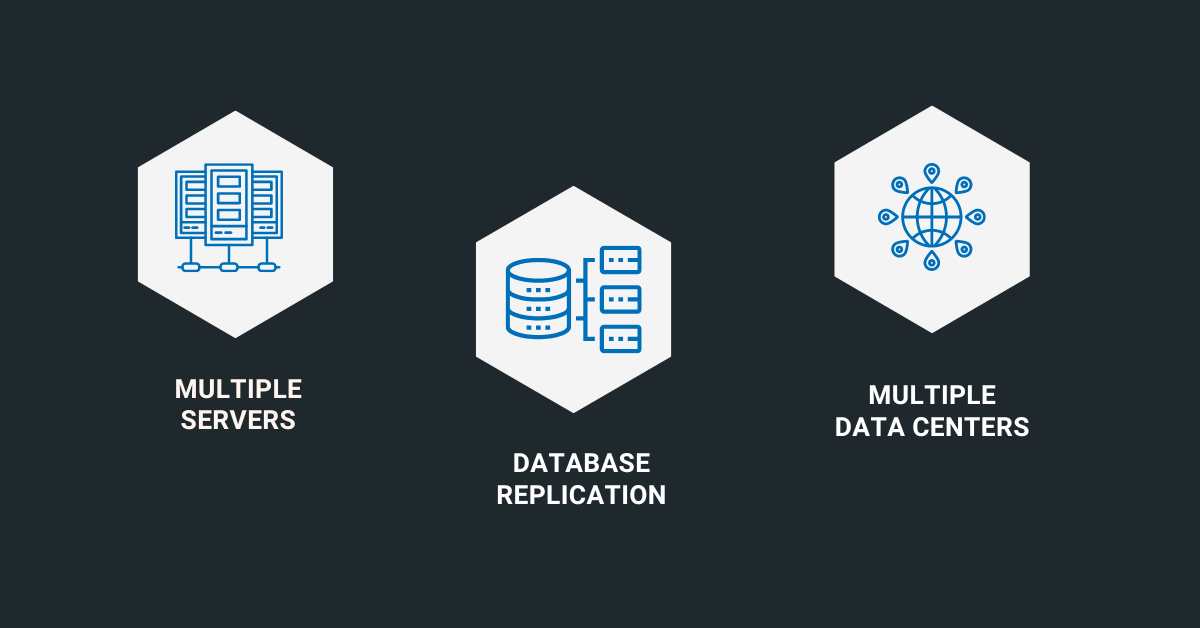
An example of a high availability system is a cloud-based web application deployed across multiple data centers with redundant servers, load balancers, and databases. In this architecture, incoming requests are distributed evenly across multiple servers using a load balancer to prevent any single server from becoming overwhelmed. Each server is equipped with redundant components, such as power supplies and network interfaces, to eliminate single points of failure. Database replication ensures that data is synchronized across multiple geographically distributed locations, providing resilience against hardware failures or data center outages. Automated failover processes detect server failures and redirect traffic to healthy servers, ensuring uninterrupted access to the application. Additionally, continuous monitoring and alerting systems track system performance and notify administrators of any issues that require attention.
High availability vs disaster recovery
High availability (HA) ensures continuous access to systems by using redundancy and automated failover mechanisms, minimizing downtime during minor failures. Disaster recovery (DR) focuses on restoring systems and data after major events like cyberattacks. While HA prevents disruptions, DR ensures recovery from significant outages.
High availability vs fault tolerance
High availability (HA) minimizes downtime by using redundancy and failover mechanisms, allowing quick recovery after failures. Fault tolerance ensures systems operate without interruption during failures, using advanced technology to prevent downtime entirely. HA is cost-effective for most needs, while fault tolerance suits environments demanding zero disruption.
High availability requirements and best practices: how do you design highly available architecture?
Designing highly available architecture involves careful consideration of redundancy, fault tolerance, scalability, monitoring, data protection, security, and continuous testing.
1. Redundancy
Redundancy lies at the core of high availability architecture. It involves duplicating critical components of your system to eliminate single points of failure. This redundancy can be achieved at various levels, including hardware, network, and data. For instance, deploying redundant servers, storage devices, and network paths ensures that if one component fails, there's another one ready to take over seamlessly.
2. Fault Tolerance
While redundancy aims to minimize the impact of failures, fault tolerance focuses on the system's ability to continue operating correctly in the presence of faults. Fault-tolerant systems are designed to detect and isolate failures without interrupting service. This often involves implementing self-healing mechanisms, such as automatic failover and graceful degradation, to maintain essential functionality even when certain components malfunction.
3. Scalability
High availability architecture should be inherently scalable to accommodate growing demands and sudden spikes in traffic. Scalability can be achieved through horizontal scaling (adding more instances of resources) or vertical scaling (upgrading existing resources). Implementing load balancing mechanisms ensures that incoming requests are distributed evenly across multiple servers, preventing any single server from becoming overwhelmed.
4. Monitoring and Alerting
Continuous monitoring of system health and performance is crucial for early detection of issues that could potentially lead to downtime. Monitoring tools should track key metrics such as CPU utilization, memory usage, network latency, and application responsiveness. Automated alerting mechanisms should notify administrators promptly when predefined thresholds are exceeded, allowing them to take proactive measures to prevent service disruptions.
5. Data Protection and Disaster Recovery
High availability architecture should incorporate robust data protection mechanisms to safeguard against data loss and corruption. This includes regular backups, replication of data across geographically distributed locations, and implementation of disaster recovery plans. In the event of a catastrophic failure or natural disaster, having off-site backups and failover systems ensures that services can be restored quickly with minimal data loss.
6. Security
Security is an integral aspect of high availability architecture, as any compromise in security can lead to downtime or loss of sensitive data. Implementing robust security measures, such as firewalls, intrusion detection systems, encryption, and access controls, helps mitigate the risk of cyber-attacks and unauthorized access. Regular security audits and compliance checks should be conducted to ensure that the system remains resilient to emerging threats.
7. Continuous Testing and Optimization
Building a high availability architecture is not a one-time effort; it requires ongoing testing, optimization, and refinement to ensure that it meets evolving business needs and performance requirements. Regularly conducting load testing, stress testing, and disaster recovery drills helps identify weaknesses and bottlenecks before they impact production environments. Optimization efforts should focus on improving resource utilization, reducing latency, and enhancing overall system resilience.
How to measure availability
Measuring availability involves evaluating how often a system is operational and accessible to users without interruptions. It’s usually expressed as a percentage, calculated by dividing uptime (available time) by the total measurement period and multiplying by 100.
A common metric in high-availability systems is “nines” availability, which indicates how many 9’s follow the decimal in uptime percentages. For instance, five nines (99.999%) means about 5.26 minutes of downtime per year. Industries such as healthcare and finance often require this level of availability. Non-critical systems may target 99.9% (three nines) or 99.99% (four nines) instead.
To measure availability effectively, track uptime and downtime over a specified period (i.e., hourly, daily, or annually). Monitoring tools can help log service performance, capturing both planned and unplanned outages. These metrics allow businesses to ensure they meet their service level agreements (SLAs) and optimize their systems for continuous availability.
Build Resilient High Availability Architecture with Meridian IT
High availability architecture is a multifaceted approach to building resilient systems that can withstand failures and maintain continuous operation. By adhering to the fundamental requirements outlined above and implementing best practices in redundancy, fault tolerance, scalability, monitoring, data protection, security, and testing, organizations can ensure that their services remain available and reliable even in the face of adversity. Investing in high availability architecture is not just about mitigating risk—it's about safeguarding your business continuity and reputation in an increasingly competitive and unpredictable digital landscape.
Contact the experts at Meridian IT to help design the right architecture for your environment.